In the era of big data, advanced analytics, and AI, the need for efficient data management systems becomes critical. Traditional data warehousing and data lake architectures have their limitations, particularly in navigating through diverse and voluminous datasets, making it extremely difficult for users to get to relevant, contextualized data. Traditional data architectures suffer from these problems:
The need for a holistic approach

Data Accessibility
Running analytical queries on large and diverse datasets is challenging, and it becomes extremely difficult for users to find and get contextualized data out. This also means that the existing architecture can only provide limited support for advanced analytics and AI as these algorithms need to process large datasets using complex querying.

Collaboration Bottlenecks

Data Integrity Issues
The concept of a data lakehouse, which integrates the best features of both data lakes and data warehouses and adds a semantic layer for contextualization, emerges as a compelling solution.
A data lakehouse is an open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management capabilities of data warehouses. It enables dashboarding, traditional AI, generative AI, and AI-based applications on accessible and transparent data.
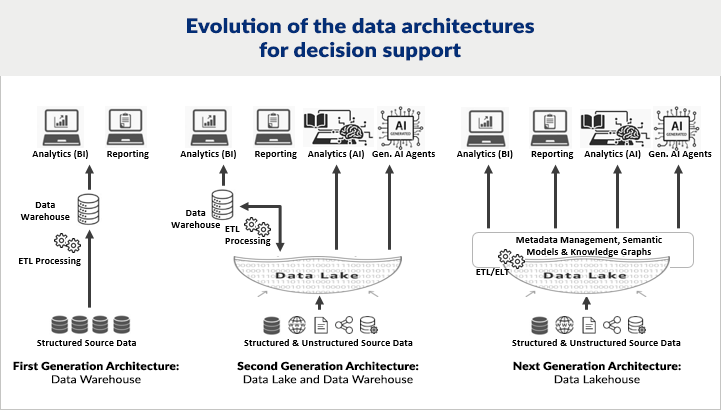
Unpacking the Data Lakehouse Advantage:
Data Ingestion (Easy to Get Data In)
Data Leverage (Easy to Get Data Out)
- By defining semantic relationships and hierarchies between data entities, knowledge graphs provide rich domain context that enhances data understanding and usability. This allows users to navigate through data based on relationships rather than just rely on raw data of technical data dictionaries.
- Connecting the Semantic Layer to the Analysis layer allows the use of contextualized semantic business terms for analytics. It enables efficient querying of data in natural language and provides contextual responses that are easy to use, understand, and interpret.
- Knowledge graphs can enrich data by linking it with external datasets or ontologies, providing additional context that can improve analysis and insights.
Creating a powerful Data Lakehouse with mcube™
This reference architecture attempts a comprehensive and complete view of all possible components that can contribute to a Data Lakehouse implementation. Depending on the scope, type of data, and the analytical processes that need to be supported, your mileage might vary in terms of functionality and required elements.
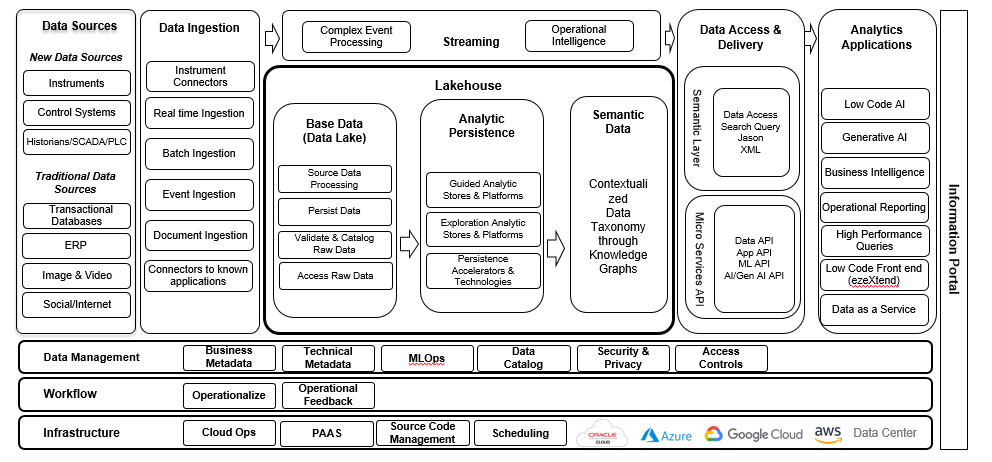
This reference architecture attempts a comprehensive and complete view of all possible components that can contribute to a Data Lakehouse implementation. Depending on the scope, type of data, and the analytical processes that need to be supported, your mileage might vary in terms of functionality and required elements.
Reference Architecture:
Leveraging our end-to-end AI platform, mcube™, organizations can create robust data lakehouses, with the aim to streamline data management by integrating various data processing and analytics needs into one architecture. This approach helps avoid redundancies and inconsistencies in data, accelerates analysis throughput, and minimizes costs.
The platform mcube™ provides advanced analytics/AI capabilities and data management on the same platform managed by common platform services. This makes it an extremely powerful platform for implementing the lakehouse and deploying analytical and AI applications on top of the lakehouse.