Transform your data into your strategic asset
mcube™ – powered Data Lakehouse
The AI & analytics foundation for all data types I Powerful semantics for better contextualization
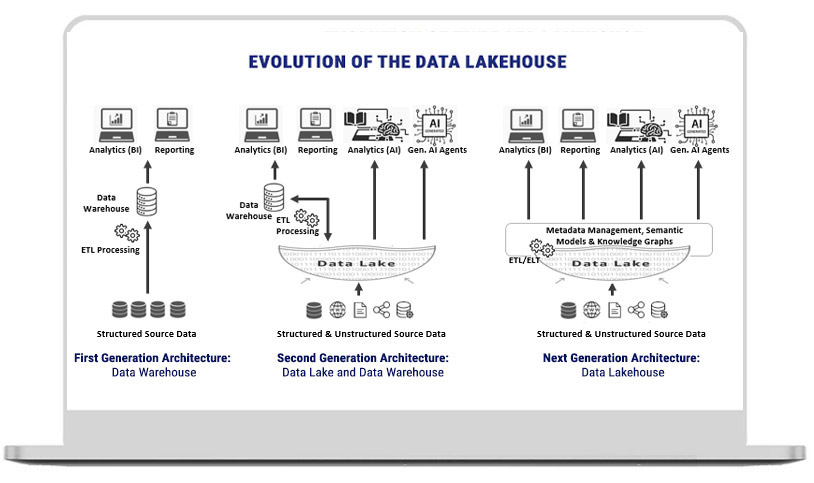
Why Modern Enterprises Need a Data Lakehouse
In the era of big data and AI, the need for efficient data management systems becomes critical. Traditional data architectures have their limitations, particularly in navigating through diverse and voluminous datasets, making it difficult for users to get to relevant, contextualized data. There are challenges around data accessibility and data integrity, as well as significant collaboration bottlenecks.
The data lakehouse, which integrates the best features of both data lakes and data warehouses and adds a semantic layer for contextualization, emerges as a compelling solution. The data lakehouse enables dashboarding, reporting, traditional AI, generative AI, and AI-based applications on accessible and transparent data.
Leveraging our end-to-end AI platform, tcgmcube, organizations can create robust data lakehouses with the aim to streamline data management by integrating various data processing and analytics needs into one architecture. This approach helps avoid redundancies and inconsistencies in data, accelerates analysis throughput, and minimizes costs, helping enterprises unlock the full potential of their data ecosystems with AI-driven insights and unified governance.
Key Benefits
Improved Data Accessibility
Facilitates actionable insights ensuring that users have easy access to the right data at the right time through the right user interface.
Seamless Collaboration
Enables teams to work together more effectively by providing a shared view of data across the organization.
Enhanced Analysis Integrity
Core components of a holistic data lakehouse strategy
Comprehensive Architecture
- AI capabilities and data management on the same platform managed by common platform services
- Distributed, fault-tolerant, and cloud-native architecture
- Cloud-agnostic platform that can make native cloud calls
- Highly interoperable – complements existing ecosystems
- Modular architecture- each module can scale dynamically
Features that make it “Easy to Get Data In”
- Streamlined data ingestion with pre-built connectors to various source systems and instruments
- Support for both real-time and batch data ingestion, ensuring flexibility and efficiency
- Enhanced ingestion process by utilizing semantic definitions for better contextualization
- Cohesive and interconnected representation using knowledge graphs to integrate the data
Features that make it “Easy to Get Data Out”
- Business metadata management powered by knowledge graphs, providing ontology management and knowledge modeling capabilities
- Adherence to FAIR (Findable, Accessible, Interoperable, and Reusable) data principles
- Enhanced data understanding and usability through rich domain-context, powered by knowledge graphs
- Use of contextualized semantic business terms for analytics, enabling efficient querying in natural language and easy interpretation of contextual responses

mcube™ taking the Data Lakehouse to the next level
The Data Ingestion Layer of mcube™ comes with pre-built standard connectors to various source systems & instruments.
- Ingestion of structured, semi-structured, and unstructured data
- Options for real-time, near real-time, and batch ingestion
- Support for dynamic data pipelines
- Options for data transformation at various stages (ETL as well as ELT)
- Support for data collection and management at the edge – handling events through data caches and synchronization
- Overlay of a semantic layer
The data storage layer comes with robust data management features. It leverages ontology and knowledge modeling capabilities, making it “easy to get data out” and has the following layers:
- Base data layer for source data processing, providing features to validate and catalogue the raw data
- Analytic Persistence layer with processed datasets for optimizing analytical queries and AI – driven processes
- Semantic Persistence Layer with contextualized data taxonomy through knowledge graphs
- Traditional AI at scale with a wide assortment of statistical, ML, DL, and optimization algorithms.
- Comprehensive Gen – AI algorithms covering traditional LLM and multimodal LLM RAG models for fast information retrieval and traceability.
- Insights dissemination options include dashboards with easy business user self-service, operational reports, and low-code “upgrade safe custom screen painting”. These leverage the semantic layer for data interpretation and reporting.
- Action dissemination options provide inputs to automated operational processes such as alerts, recommendations, action triggers, etc.
- Role-based Access Control and fine-grained access policies (row, column, and object-level access control)
- Data Encryption at rest and in transit
- Audit Logs for all data access and processing activities.
- Layered Security: Security can be defined at various levels- cluster, index, document, and field
- Metadata Management powered by knowledge graphs
Resources


