- April 17, 2025
Bad Vilbel, Germany
FrontWell Solutions, a dynamic and rapidly growing IT solutions provider with focus on Life Sciences and TCG Digital, a global leader in data intelligence & AI enabled business transformation, are pleased to announce a strategic collaboration to drive innovation in the fields of AI and advanced analytics to drive autonomous, data-driven operations.
Why This Partnership Matters
The alliance combines FrontWell’s expertise in integrating and digitizing complex Life Sciences’ production and lab environments with TCG Digital’s mcube™ platform.
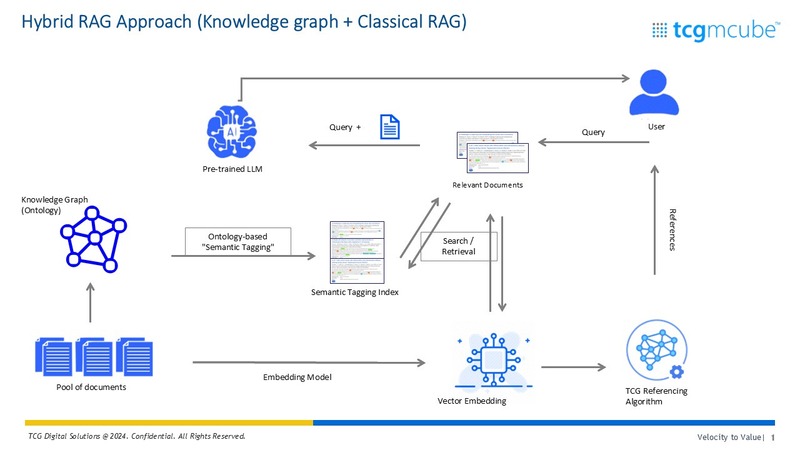
mcube™ unifies and activates data from MES, LIMS, MOM and other systems, transforming operations into self-learning, insight-rich environments. This integration accelerates digital maturity, enabling organizations to confidently advance towards AI-powered operations.
What the Partnership Enables
Accelerated Digital Maturity
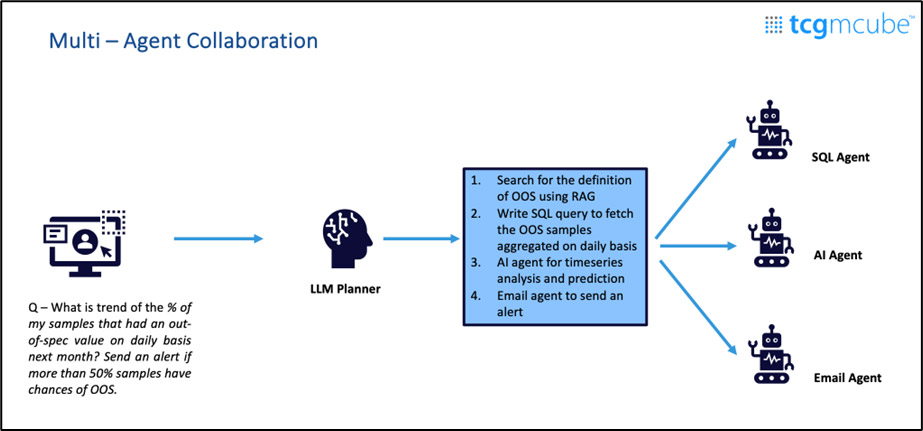
Agentic AI Capabilities
Ontologies driven intelligence layer
High impact AI applications
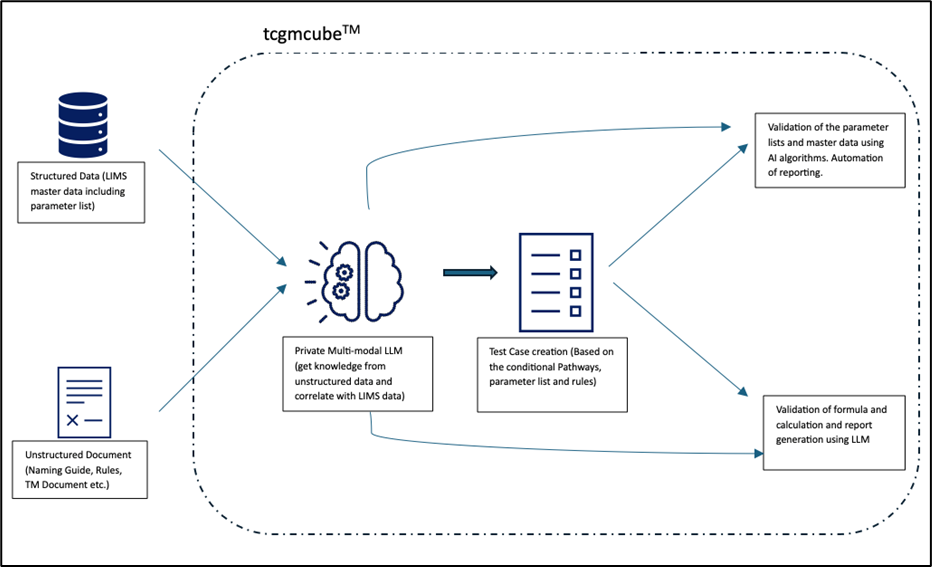
This partnership brings targeted value to labs, R&D, and QC environments by enabling high-impact use cases such as predictive formulations, bio-assay AI suite, and AI-led master data management (MDM) for LIMS.
Compliance and Traceability
Accelerated Digital Maturity
Agentic AI Capabilities
Ontologies driven intelligence layer
High impact AI applications
This partnership brings targeted value to labs, R&D, and QC environments by enabling high-impact use cases such as formulation optimization, bio-assay AI suite, and AI-led master data management (MDM) for LIMS.
Compliance and Traceability
A Partnership Built on Innovation and Strengths
This collaboration will also include joint R&D initiatives and co-hosted industry events to advance thought leadership in AI and analytics.
We are not just at the beginning of a new era – we are already amidst transformation. Artificial intelligence is not only revolutionizing our industry but fundamentally changing how our customers think, decide, and operate. This paradigm shift presents tremendous opportunities. Integrating AI into leveraging the Data from the industrial processes is no longer just an option but a strategic necessity. That’s why we are strategically investing in AI and analytics – and we are particularly excited about partnering with one of the leading innovators in this field, TCG Digital.” said Ardavan Heidari, CEO of FrontWell Solutions.
The capabilities of mcube™ in harmonizing complex data and enabling advanced AI-driven decision-making to represent a significant advancement in operational intelligence. This partnership will fundamentally enhance how data is processed and utilized across labs and production lines, increasing reliability of production processes manifold, driving improved efficiency and compliance.” said Arunava Mitra, VP, TCG Digital.

FrontWell Solutions is an expert in the digital transformation of the Life Sciences manufacturing process. Our team of experts is engaged in providing digital solutions to 12 of the 20-leading pharmaceutical, biotechnology, chemical, and medical device companies and suppliers spanning Europe, the United States, and Asia.
Our expertise lies in delivering specialized consulting services, primarily centered around Manufacturing Execution Systems (MES), Laboratory Information Management Systems (LIMS), seamlessly integrating these Level 3 systems with Enterprise Resource Planning (ERP) platforms and driving Manufacturing Intelligence initiatives such as Overall Equipment Effectiveness (OEE) reporting.
TCG Digital is the digital & AI arm of The Chatterjee Group (TCG), a multi-billion dollar conglomerate with a diverse portfolio in Pharmaceuticals, Biotech, Petrochemicals, Aviation, Process Manufacturing across the US, EU, and South Asia. Our umbrella includes companies such as LabVantage, Lummus Technology, and TCG LifeSciences. At TCG Digital, we are driven by our mantra of delivering “Velocity to Value”, helping enterprises achieve topline growth and margin enhancements while strengthening their bottom-line. Our AI Analytics platform mcube is at the heart of these transformations. We enable organizations unlock the full potential of their data, and by seamlessly integrating AI/ML capabilities into their business processes, we empower them to accelerate their digital transformation journey, enhancing agility and driving impactful results.
Media Inquiries:
Julia Tantzky
Marketing & Communications Coordinator
Email: julia.tantzky@frontwell-solutions.com
Phone: +49 170 1789 519
Aditi Basu
Senior Director – Global Marketing
Email: Aditi.Basu@tcgdigital.com
Phone: +919830054094